Category: Benchmarks
-
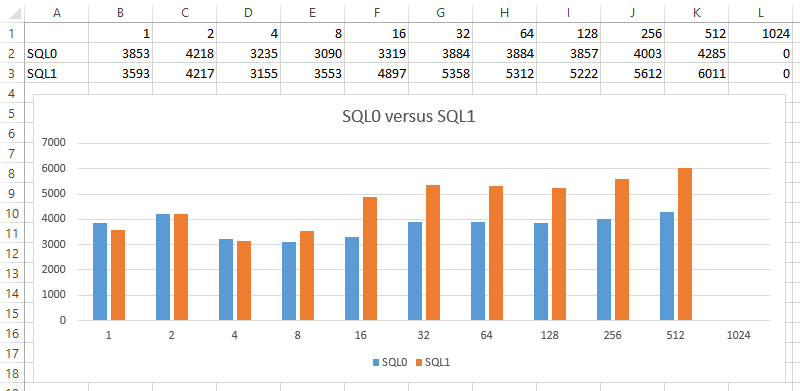
Intro to HammerDB
One of my favorite benchmarking tools is HammerDB. In a nutshell, it allows you to run a well evolved SQL benchmark (TPC-C) against your system to gauge performance. The scenario to picture is an order/warehouse simulator and your metric is how many new orders per minute (NOPM) the system can crank out. CPU, memory, disk all matter […]
-
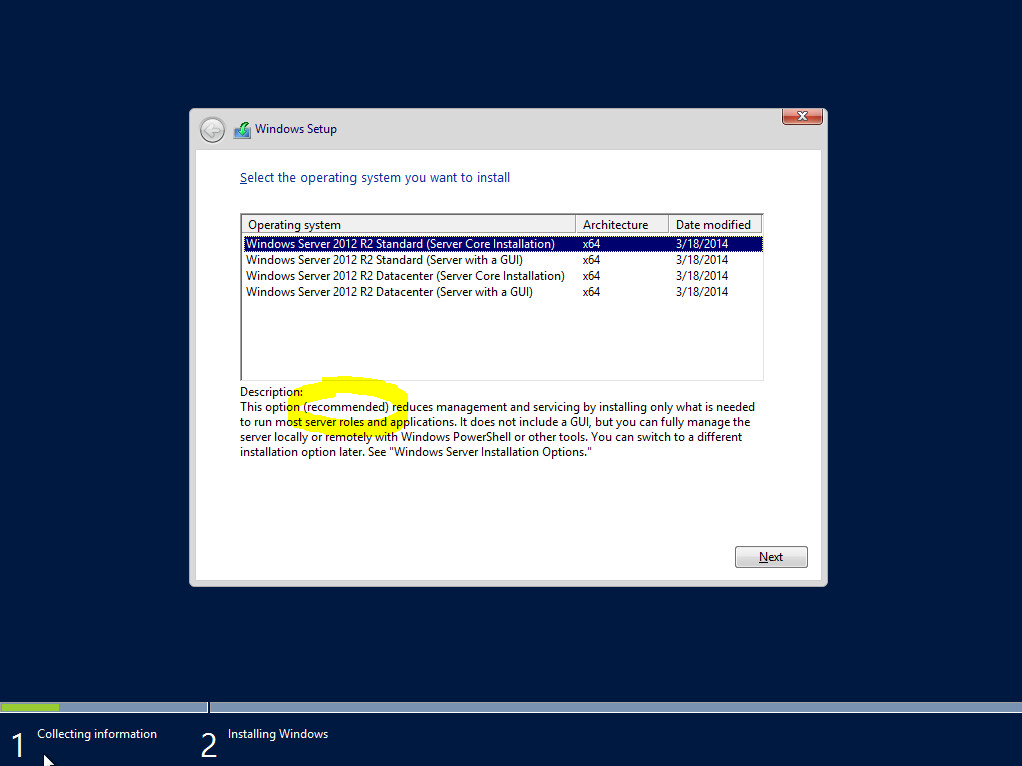
Core versus Full – Initial install quick stats
Created two VM’s with identical resources. On the first VM, Windows 2012 R2 Core Installation was chosen. On the second VM, Windows 2012 R2 Server with a GUI (Full) was chosen. After installation of both, I also ran updates on both until no more Windows updates were found. Here are the quick stats: Core has […]