Category: How-to
-
Commands to overcome file folder path issues
Delete folder with space at the end for instance “Z:\WEB\Feature Page\CK ” rmdir /S “\\?\Z:\WEB\Feature Page\CK ” The file name is too long – shorten the path by substituting a drive letter for a portion of the path subst Y: D:\this\file\path\is\waaaay\too\long Y: dir subst Y: /D
-
Hyper-V server on USB
Pre-requisites: Download GImageX Download the latest Hyper-V ISO Create VHD Put in the USB drive diskpart select disk 3 clean create partition primary select partition 1 active format quick fs=ntfs assign letter=z create vdisk file=z:\hyperv1.vhd maximum=24576 type=fixed select vdisk file=z:\hyperv1.vhd attach vdisk create partition primary assign letter=r format quick fs=ntfs label=hyperv1 exit Apply WIM to […]
-
Installing SQL on core
For example .. setup.exe /q /iacceptsqlserverlicenseterms /action=install /features=sqlengine,replication /instanceid=SQLEXPRESS /instancename=SQLEXPRESS /usemicrosoftupdate OR you can force enable the UI if (really?) necessary setup.exe /uimode=EnableUIonServerCore Don’t forget your firewall allow rules netsh advfirewall firewall add rule name=”Allow SQL TCP 54321″ protocol=TCP dir=in localport=54321 action=allow netsh advfirewall firewall add rule name=”Allow SQL UDP 1434″ protocol=UDP dir=in localport=1434 action=allow […]
-
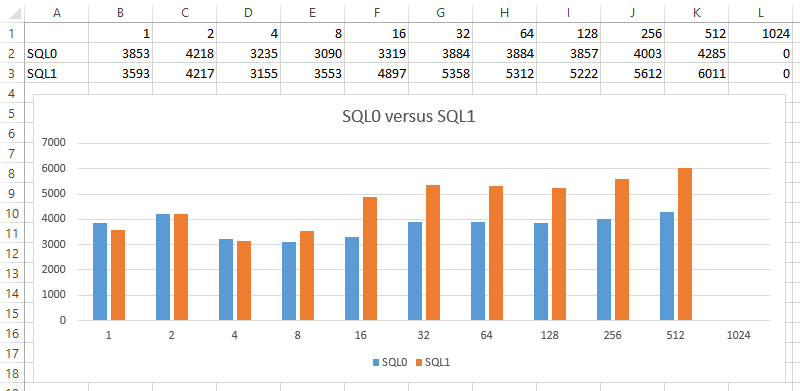
Intro to HammerDB
One of my favorite benchmarking tools is HammerDB. In a nutshell, it allows you to run a well evolved SQL benchmark (TPC-C) against your system to gauge performance. The scenario to picture is an order/warehouse simulator and your metric is how many new orders per minute (NOPM) the system can crank out. CPU, memory, disk all matter […]